mirror of
https://github.com/ralsina/tartrazine.git
synced 2024-11-10 13:32:24 +00:00
This change names the dependency like its called. The link to the package was correct, but all other references were renamed where I could find time with git grep. Signed-off-by: Zeger-Jan van de Weg <git@zjvandeweg.nl>
245 lines
8.4 KiB
Markdown
245 lines
8.4 KiB
Markdown
# enry [](https://godoc.org/gopkg.in/src-d/enry.v1) [](https://travis-ci.org/src-d/enry) [](https://codecov.io/gh/src-d/enry)
|
|
|
|
File programming language detector and toolbox to ignore binary or vendored files. *enry*, started as a port to _Go_ of the original [linguist](https://github.com/github/linguist) _Ruby_ library, that has an improved *2x performance*.
|
|
|
|
|
|
Installation
|
|
------------
|
|
|
|
The recommended way to install enry is
|
|
|
|
```
|
|
go get gopkg.in/src-d/enry.v1/...
|
|
```
|
|
|
|
To build enry's CLI you must run
|
|
|
|
make build-cli
|
|
|
|
this will generate a binary in the project's root directory called `enry`. You can then move this binary to anywhere in your `PATH`.
|
|
|
|
|
|
### Faster regexp engine (optional)
|
|
|
|
[Oniguruma](https://github.com/kkos/oniguruma) is CRuby's regular expression engine.
|
|
It is very fast and performs better than the one built into Go runtime. *enry* supports swapping
|
|
between those two engines thanks to [rubex](https://github.com/moovweb/rubex) project.
|
|
The typical overall speedup from using Oniguruma is 1.5-2x. However, it requires CGo and the external shared library.
|
|
On macOS with brew, it is
|
|
|
|
```
|
|
brew install oniguruma
|
|
```
|
|
|
|
On Ubuntu, it is
|
|
|
|
```
|
|
sudo apt install libonig-dev
|
|
```
|
|
|
|
To build enry with Oniguruma regexps, patch the imports with
|
|
|
|
```
|
|
make oniguruma
|
|
```
|
|
|
|
and then rebuild the project.
|
|
|
|
Examples
|
|
------------
|
|
|
|
```go
|
|
lang, safe := enry.GetLanguageByExtension("foo.go")
|
|
fmt.Println(lang, safe)
|
|
// result: Go true
|
|
|
|
lang, safe := enry.GetLanguageByContent("foo.m", []byte("<matlab-code>"))
|
|
fmt.Println(lang, safe)
|
|
// result: Matlab true
|
|
|
|
lang, safe := enry.GetLanguageByContent("bar.m", []byte("<objective-c-code>"))
|
|
fmt.Println(lang, safe)
|
|
// result: Objective-C true
|
|
|
|
// all strategies together
|
|
lang := enry.GetLanguage("foo.cpp", []byte("<cpp-code>"))
|
|
// result: C++ true
|
|
```
|
|
|
|
Note that the returned boolean value `safe` is set either to `true`, if there is only one possible language detected, or to `false` otherwise.
|
|
|
|
To get a list of possible languages for a given file, you can use the plural version of the detecting functions.
|
|
|
|
```go
|
|
langs := enry.GetLanguages("foo.h", []byte("<cpp-code>"))
|
|
// result: []string{"C", "C++", "Objective-C}
|
|
|
|
langs := enry.GetLanguagesByExtension("foo.asc", []byte("<content>"), nil)
|
|
// result: []string{"AGS Script", "AsciiDoc", "Public Key"}
|
|
|
|
langs := enry.GetLanguagesByFilename("Gemfile", []byte("<content>"), []string{})
|
|
// result: []string{"Ruby"}
|
|
```
|
|
|
|
|
|
CLI
|
|
------------
|
|
|
|
You can use enry as a command,
|
|
|
|
```bash
|
|
$ enry --help
|
|
enry v1.5.0 build: 10-02-2017_14_01_07 commit: 95ef0a6cf3, based on linguist commit: 37979b2
|
|
enry, A simple (and faster) implementation of github/linguist
|
|
usage: enry <path>
|
|
enry [-json] [-breakdown] <path>
|
|
enry [-json] [-breakdown]
|
|
enry [-version]
|
|
```
|
|
|
|
and it'll return an output similar to *linguist*'s output,
|
|
|
|
```bash
|
|
$ enry
|
|
55.56% Shell
|
|
22.22% Ruby
|
|
11.11% Gnuplot
|
|
11.11% Go
|
|
```
|
|
|
|
but not only the output; its flags are also the same as *linguist*'s ones,
|
|
|
|
```bash
|
|
$ enry --breakdown
|
|
55.56% Shell
|
|
22.22% Ruby
|
|
11.11% Gnuplot
|
|
11.11% Go
|
|
|
|
Gnuplot
|
|
plot-histogram.gp
|
|
|
|
Ruby
|
|
linguist-samples.rb
|
|
linguist-total.rb
|
|
|
|
Shell
|
|
parse.sh
|
|
plot-histogram.sh
|
|
run-benchmark.sh
|
|
run-slow-benchmark.sh
|
|
run.sh
|
|
|
|
Go
|
|
parser/main.go
|
|
```
|
|
|
|
even the JSON flag,
|
|
|
|
```bash
|
|
$ enry --json
|
|
{"Gnuplot":["plot-histogram.gp"],"Go":["parser/main.go"],"Ruby":["linguist-samples.rb","linguist-total.rb"],"Shell":["parse.sh","plot-histogram.sh","run-benchmark.sh","run-slow-benchmark.sh","run.sh"]}
|
|
```
|
|
|
|
Note that even if enry's CLI is compatible with linguist's, its main point is that **_enry doesn't need a git repository to work!_**
|
|
|
|
Java bindings
|
|
------------
|
|
|
|
Generated Java binidings using a C shared library + JNI are located under [`java`](https://github.com/src-d/enry/blob/master/java)
|
|
|
|
Development
|
|
------------
|
|
|
|
*enry* re-uses parts of original [linguist](https://github.com/github/linguist) to generate internal data structures. In order to update to the latest upstream and generate the necessary code you must run:
|
|
|
|
go generate
|
|
|
|
We update enry when changes are done in linguist's master branch on the following files:
|
|
|
|
* [languages.yml](https://github.com/github/linguist/blob/master/lib/linguist/languages.yml)
|
|
* [heuristics.rb](https://github.com/github/linguist/blob/master/lib/linguist/heuristics.rb)
|
|
* [vendor.yml](https://github.com/github/linguist/blob/master/lib/linguist/vendor.yml)
|
|
* [documentation.yml](https://github.com/github/linguist/blob/master/lib/linguist/documentation.yml)
|
|
|
|
Currently we don't have any procedure established to automatically detect changes in the linguist project and regenerate the code.
|
|
So we update the generated code as needed, without any specific criteria.
|
|
|
|
If you want to update *enry* because of changes in linguist, you can run the *go
|
|
generate* command and do a pull request that only contains the changes in
|
|
generated files (those files in the subdirectory [data](https://github.com/src-d/enry/blob/master/data)).
|
|
|
|
To run the tests,
|
|
|
|
make test
|
|
|
|
|
|
Divergences from linguist
|
|
------------
|
|
|
|
Using [linguist/samples](https://github.com/github/linguist/tree/master/samples)
|
|
as a set for the tests, the following issues were found:
|
|
|
|
* With [hello.ms](https://github.com/github/linguist/blob/master/samples/Unix%20Assembly/hello.ms) we can't detect the language (Unix Assembly) because we don't have a matcher in contentMatchers (content.go) for Unix Assembly. Linguist uses this [regexp](https://github.com/github/linguist/blob/master/lib/linguist/heuristics.rb#L300) in its code,
|
|
|
|
`elsif /(?<!\S)\.(include|globa?l)\s/.match(data) || /(?<!\/\*)(\A|\n)\s*\.[A-Za-z][_A-Za-z0-9]*:/.match(data.gsub(/"([^\\"]|\\.)*"|'([^\\']|\\.)*'|\\\s*(?:--.*)?\n/, ""))`
|
|
|
|
which we can't port.
|
|
|
|
* All files for the SQL language fall to the classifier because we don't parse
|
|
this [disambiguator
|
|
expression](https://github.com/github/linguist/blob/master/lib/linguist/heuristics.rb#L433)
|
|
for `*.sql` files right. This expression doesn't comply with the pattern for the
|
|
rest in [heuristics.rb](https://github.com/github/linguist/blob/master/lib/linguist/heuristics.rb).
|
|
|
|
|
|
Benchmarks
|
|
------------
|
|
|
|
Enry's language detection has been compared with Linguist's one. In order to do that, linguist's project directory [*linguist/samples*](https://github.com/github/linguist/tree/master/samples) was used as a set of files to run benchmarks against.
|
|
|
|
We got these results:
|
|
|
|
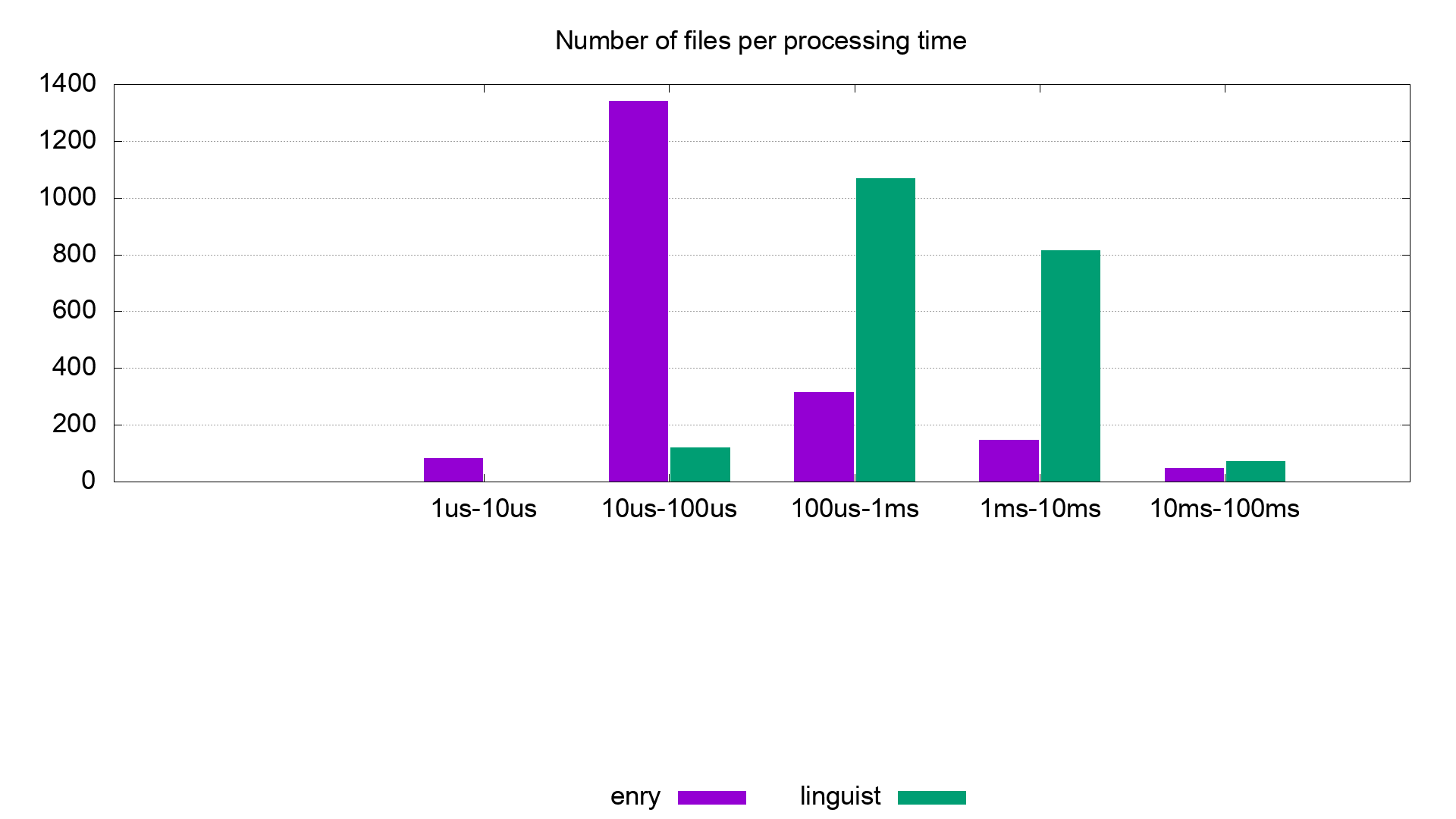
|
|
|
|
The histogram represents the number of files for which spent time in language
|
|
detection was in the range of the time interval indicated in the x axis.
|
|
|
|
So you can see that most of the files were detected quicker in enry.
|
|
|
|
We found some few cases where enry turns slower than linguist. This is due to
|
|
Golang's regexp engine being slower than Ruby's, which uses the [oniguruma](https://github.com/kkos/oniguruma) library, written in C.
|
|
|
|
You can find scripts and additional information (like software and hardware used
|
|
and benchmarks' results per sample file) in [*benchmarks*](https://github.com/src-d/enry/blob/master/benchmarks) directory.
|
|
|
|
If you want to reproduce the same benchmarks you can run:
|
|
|
|
benchmarks/run.sh
|
|
|
|
from the root's project directory and it'll run benchmarks for enry and linguist, parse the output, create csv files and create a histogram (you must have installed [gnuplot](http://gnuplot.info) in your system to get the histogram).
|
|
|
|
This can take some time, so to run local benchmarks for a quick check you can either:
|
|
|
|
make benchmarks
|
|
|
|
to get average times for the main detection function and strategies for the whole samples set or:
|
|
|
|
make benchmarks-samples
|
|
|
|
if you want to see measures by sample file.
|
|
|
|
|
|
Why Enry?
|
|
------------
|
|
|
|
In the movie [My Fair Lady](https://en.wikipedia.org/wiki/My_Fair_Lady), [Professor Henry Higgins](http://www.imdb.com/character/ch0011719/?ref_=tt_cl_t2) is one of the main characters. Henry is a linguist and at the very beginning of the movie enjoys guessing the origin of people based on their accent.
|
|
|
|
`Enry Iggins` is how [Eliza Doolittle](http://www.imdb.com/character/ch0011720/?ref_=tt_cl_t1), [pronounces](https://www.youtube.com/watch?v=pwNKyTktDIE) the name of the Professor during the first half of the movie.
|
|
|
|
|
|
License
|
|
------------
|
|
|
|
Apache License, Version 2.0. See [LICENSE](LICENSE)
|